
今回は多変量解析の統計手法の1つである、「重回帰分析」についてまとめてみました。
「重回帰分析」は研究でよく使用される統計手法であり、さまざまなことがわかる方法ですので、理解していると論文を読むときにも、実際に研究を行うときにもとても強みになります。
それには多変量解析を理解しておく必要がありますが、多変量解析の基礎に関しては以下のサイトにまとめてありますので、参考にしてください。
今回もデモデータを使用してわかりやすく実践していきます。
EZRを使っていきますが、EZRの導入については以下のサイトをご確認ください。
データのインポートについては以下のサイトをご確認ください。
簡単に実践できるようにまとめてみました。
スポンサードサーチ
多変量解析の選択
多変量解析を行うにはまずは、統計手法を選択する必要があります。
今回は「重回帰分析」を行いますが、「重回帰分析」は従属変数が連続変数の場合に使用する検定になります。
| 従属変数 | 回帰モデル |
| 連続変数、順序変数の場合 | ➡︎ 重回帰分析 |
| 名義変数(2値変数)の場合 | ➡︎ ロジスティック回帰分析 |
| 生存期間の場合 | ➡︎ Cox比例ハザード回帰分析 |
重回帰分析の実践
今回もデモデータを使用して重回帰分析を実践していきます。
デモデータとしては、COPD患者50例の身体機能評価を使用することとします。
身体機能の「歩行速度」を従属変数として、「膝伸展筋力」を独立変数の1つとして、「膝伸展筋力が歩行速度にどれほど影響するか」を調べたいとします。
歩行速度は、連続変数になりますので、先ほど説明したように多変量解析の「重回帰分析」が選択されます。
変数については以下のサイトを参考にしてください。
独立変数の投入可能因子を決定
多変量解析(重回帰分析)を行う際の注意点として、独立変数をなんでもかんでも投入できるわけではなく、投入可能な数が「n数(症例数)」によって決まるということです。
以下に多変量解析の方法によって、投入可能な独立変数の目安を表示します。
| 回帰モデル | 独立変数の個数 |
| 重回帰分析 | 総症例数を15で割った数まで(10で割った数としている教科書もあり) |
| ロジスティック回帰分析 | イベントありとなし(2値の)小さい方の数を10で割った数まで |
| Cox比例ハザート回帰分析 | イベントありの数を10で割った数まで |
参考教科書:みんなの医療統計(多変量解析編) P208
*教科書によっても違いがあるので、若干の個数の変化は許容されるかもしれませんが、おおよそ上記の個数が目安となります。
独立変数の決定と投入可能数に関しては以下のサイトに詳しくまとめてますので参考にしてください。
今回は症例数50例であり、重回帰分析ですので、50例÷15〜50例÷10程度が投入可能な独立変数となりますので、だいたい3〜5つとなります。
そこで、今回のデモとしては、
従属変数は「歩行速度」
独立変数は、
①「膝伸展筋力」・・・今回「歩行速度」への影響を調査したい因子
②「年齢」・・・先行研究から「歩行速度」との関連がすでにわかっている因子
③「性別」・・・先行研究から「歩行速度」との関連がすでにわかっている因子
の3つを選択して、交絡因子を考慮して①を調査していくこととします。
EZRで重回帰分析を実施
データの確認が行えたら、実際にEZRで重回帰分析を行なっていきます。
統計解析→連続変数の解析→線形回帰(単回帰、重回帰)を選択します。
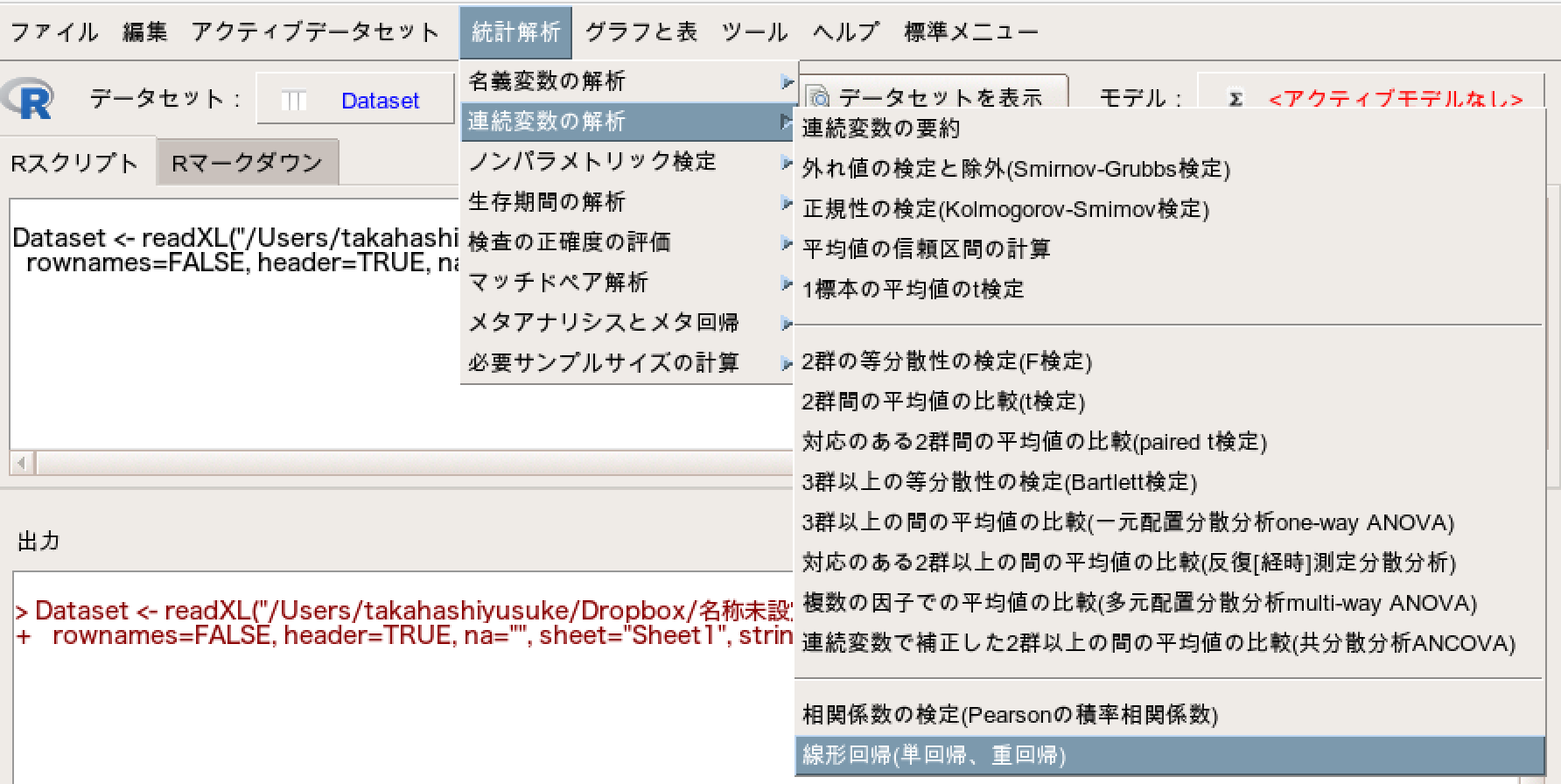
次に、目的変数(従属変数)に「歩行速度:gait speed」を選択し、説明変数(独立変数)に「膝伸展筋力:QF、年齢:age、性別:sex」を選択して「OK」をクリックします。
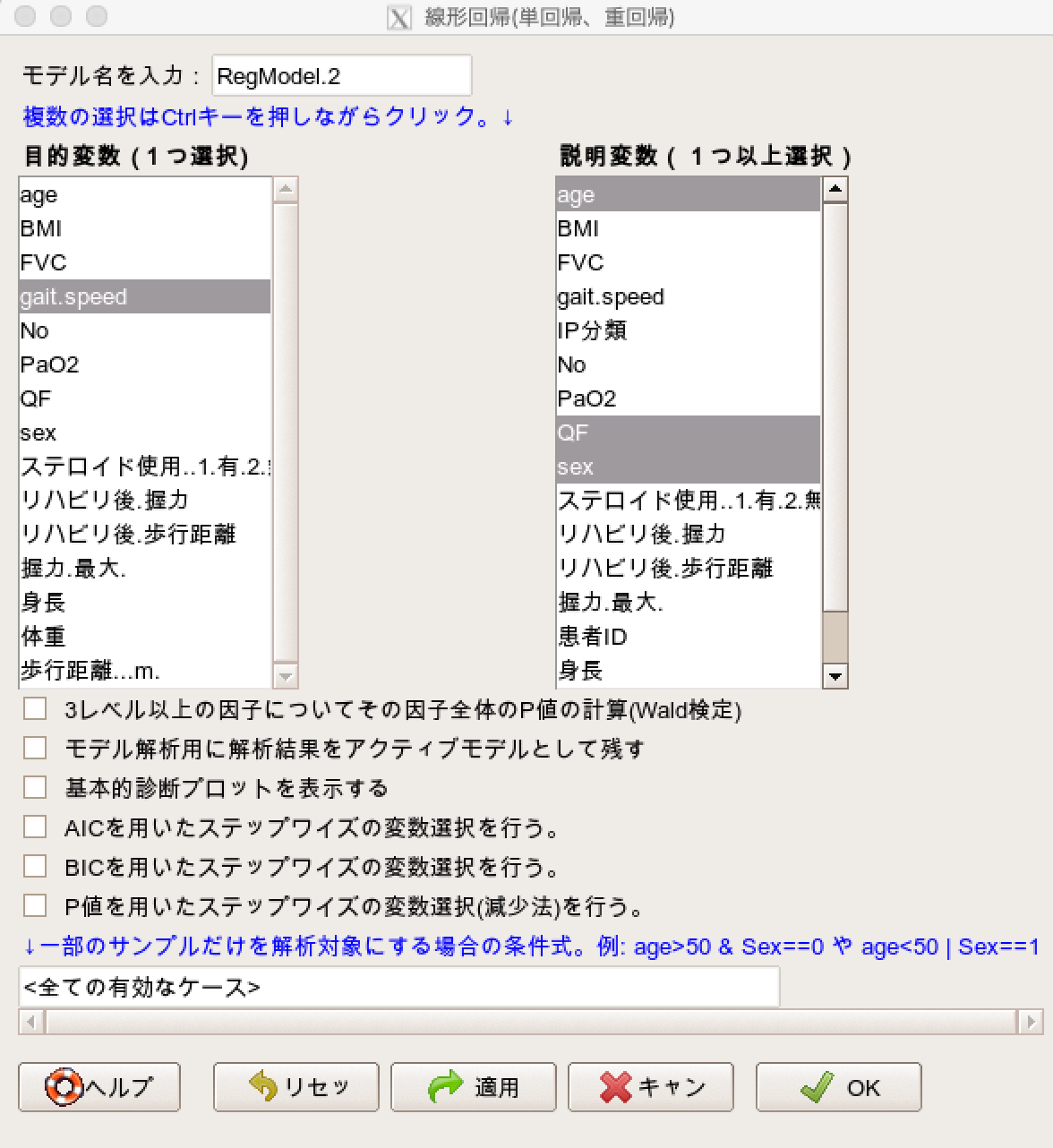
これで簡単に結果が表示されます。
重回帰分析の結果解釈
第一に確認すべきは、モデル全体のP値です。
少しみにくいですが、赤丸の「p-value」を確認します。

これは重回帰分析で算出した予測式が有意であるかを表しています。
以下のようなイメージ図ですね。

P<0.05の場合は、有意な予測式だといえます。
今回はP=0.02ですので、有意な予測式にあてはまります。
(ここがP≧0.05であった場合は、そもそもモデル自体が悪く、予測式自体がなりたたないことになります。)
次に確認するところは、先ほどと同じ結果内にある赤丸の「Adjusted R-squared」です。

これは「自由度調整済み決定係数」と呼ばれ、1に近いほどモデルの当てはまりがいいことを表しています。
ちなみに、赤丸の隣の「Multiple R-squared」は「決定係数」になります
決定係数:回帰式の予測精度を意味します。決定係数は、0から1までの値となり、1に近いほど回帰直線が観測データに合致しています。(モデルの当てはまりがいい)。一般に、決定係数は0.5以上が望ましいといわれています。
自由度調整済み決定係数:説明変数(独立変数)の数やサンプルサイズによって、決定係数を再計算したものです。通常、論文では自由度調整済み決定係数の値を記載します。
ちなみに、「〇〇以下だと使えない」というものではなく、モデルの妥当性を示すものになります。
今回のデモデータでは、P<0.05であるため予測式としては使えますが、「自由度調整済み決定係数」が0.12ですので、式自体のあてはまりはよくないと認識しないといけません。
論文などでは、「調整済みR2=〇〇」と記載されている場合が多いです。
次に重回帰分析の予測式の個々の結果をみていいきます。以下のような結果がEZRで表示されています。

これが今回の中心となる結果です。
まずは以下の赤丸で囲んだ「Estimate」をみていきます。

Estimateとは「回帰係数推定値」と呼ばれています。
今回の結果では、Intercept(切片)が「1.09」であり、ageは「-0.005」、QFは「0.17」、sexは「0.05」となっています。
*今回のデータでは性別を「男性・女性」ではなく「0・1」で表しています。(男性=0、女性=1)
EZRではデータの値を文字(日本語、英語、記号)で入力すると自動的に名義変数とみなします。
ですので、「男性・女性」と入力していていも普段は構わないのですが(私は常に数字に置き換えています)、多変量解析では、このように従属変数に対する予測式をみるときのために「0・1」にしています。
これで以下のような予測式になることがわかります。
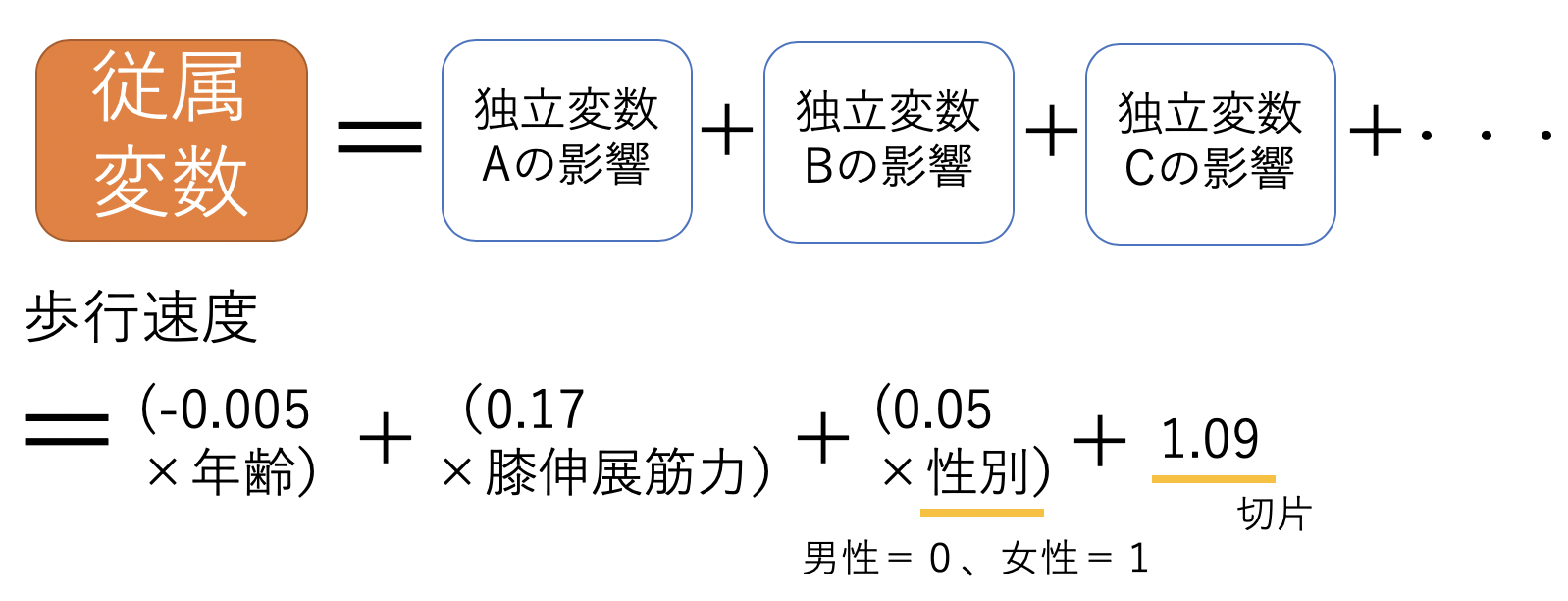
重回帰分析を行うと、このような予測式が完成できます。(精度は先ほどの、P
値や調整済みR2を確認しないといけません)
次に、赤丸のP値をみていきます。

このP値をみることで、どの独立変数が有意な影響を与えているかをしることができます。P<0.05の場合に「有意な影響あり」と判断できます。
*P≧0.05の場合も有意差はでないが、全く影響がないわけではありません。
今回のデモデータの結果では、QFのみがP<0.05になっています(IntercertのP値は関係ありません)
ここで、ほとんど結果がでたのですが、VIFの確認が必要です。
VIF(Variance Inflation Factor)は多重共線性と呼ばれ、独立変数間での相関を調べる指標になります。
独立変数同士に強い相関がありすぎると、統計学的に問題が生じてしまうので必ず確認が必要になります。
一般的にVIFが、
5以上:多重共線性の可能性あり
10以上:多重共線性の可能性がかなり高い
と判断します。
EZRでは、以下のように表示されます。
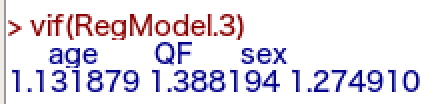
今回はいずれも2未満であり、多重共線性の問題はなさそうです。
(5以上であれば独立変数の投入を再考する必要があります。)
重回帰分析の結果を多重共線性も確認したことで、
「性別、年齢を考慮しても(補正した状態でも)、QF(膝伸展筋力)は歩行速度に有意な影響を与える独立した関連因子であった」と結論づけることができます。
スポンサードサーチ
まとめ
今回は多変量解析のなかの、従属変数が連続変数である「重回帰分析」についてまとめてみました。
EZRを使用すると簡単に結果をだすことができます。
決定係数、回帰係数、多重共線性など、確認すべきところは多いですが、理解できると簡単に実践できます。
研究が多変量解析まで行えているかどうかで、研究の信頼性は格段にアップします。
また、論文を読むときの研究の理解力も変わってきます。
少しでも参考になれば幸いです。
**その他のEZRの使い方/統計手法について以下のサイトにまとめていますので参考にしてください**



