
論文を読んでいたり、統計について学んでいると「多変量解析」という用語は度々目にすると思います。
重要そうなことはわかっていても、よく理解できていない方も多いのではないのでしょうか?
(研究者には基礎的ですが、私が数年前まで理解していませんでしたので・・・)
今回は、統計学の用語知識として「多変量解析」について簡単にまとめたいと思います。
「多変量解析」を理解して、研究で使用できると、とても質の高い研究が行えますので、是非理解しておきたいところです。
スポンサードサーチ
目次
多変量解析とは
教科書をみてみるといろいろ書かれています。
複数のデータ(3変数以上)の関係や差をまとめて解析する、いくつかの手法全般です。
参考:臨床研究 first stage p215より
であったり、
多くの変数の相互関係を表す関係式を作成し、いろいろなテーマを解決する方法です。
参考:すぐできる!リハビリテーション統計 p95
であったり、
ある結果を表す変数をその他の変数によってどの程度説明(予測)できるか
参考:フリー統計ソフトEZRで誰でも簡単統計解析 p151
など書かれています。・・・わかるようでまだわかりにくいですよね。
以下のような図を使ってイメージするとわかりやすいです。
調べたい「ある結果」は、ひとつの因子で決まるわけではありません。
「様々な因子」が影響することで決定されます。
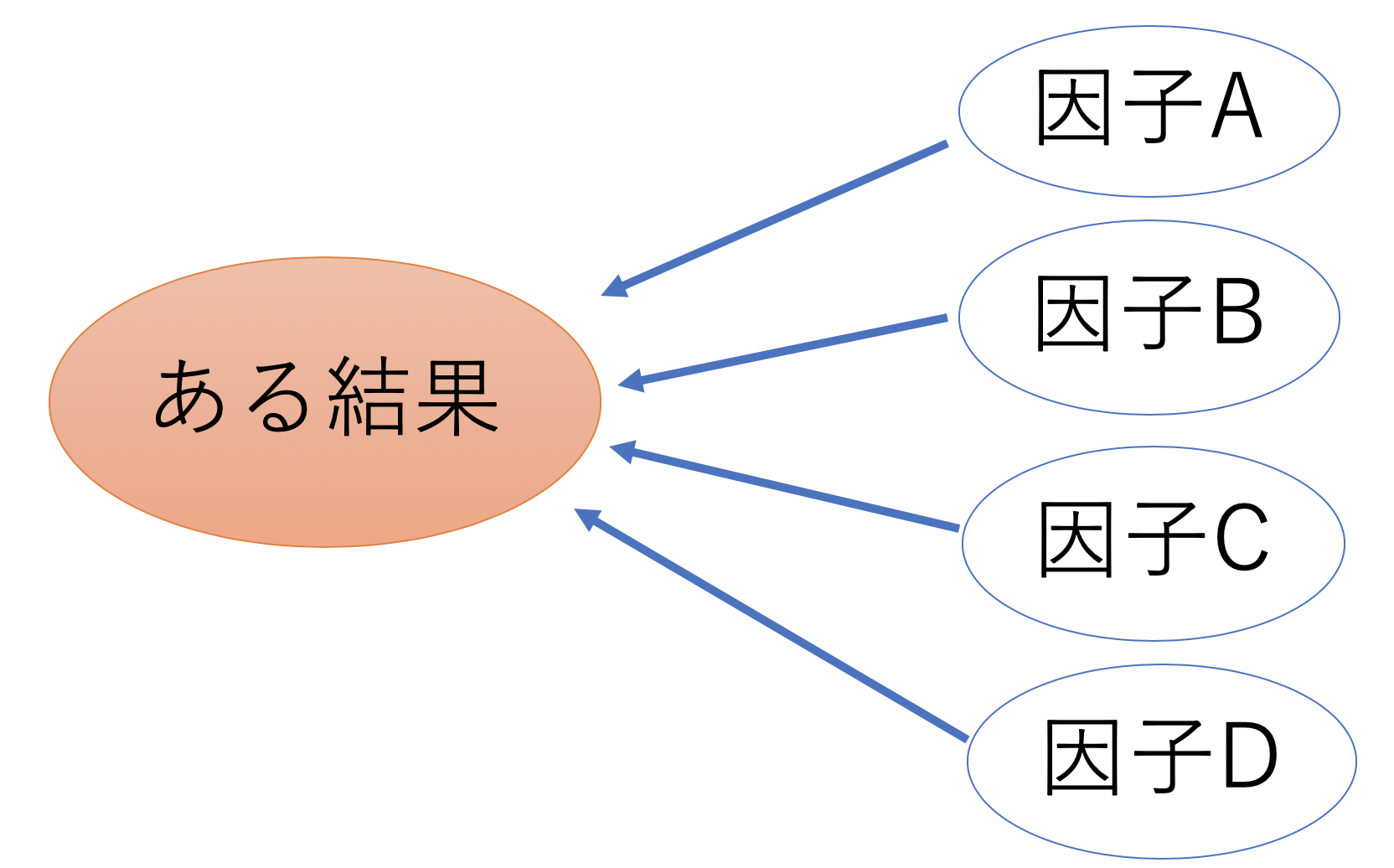
このように、「ある結果」は様々なな因子の影響を受けて決定しますので、「ある結果」と「因子A」だけの関係性を確認して、「ある結果は因子Aに影響する!」とは言えません。
「ある結果」と「因子A」だけの関係は、「相関」としてみることができるだけです。
*相関に関してはEZRで実践する方法を以下のサイトにまとめてあるので参考にしてください。
「ある結果」は「様々な因子」の影響をうけているので、本当に「因子A」単独が「ある結果」を影響するかは、「交絡因子」を調査して、「因子B、C、D」と一緒に解析する必要があります。
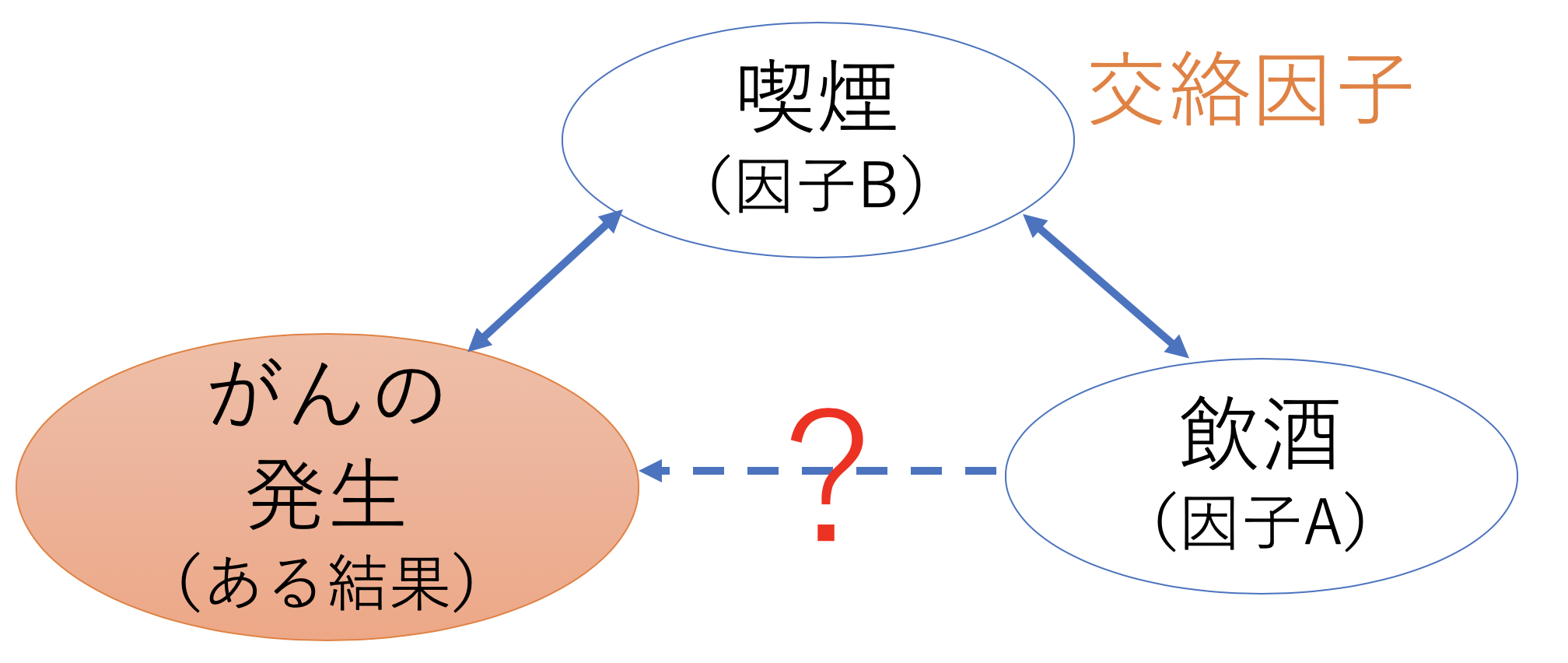
ここで注意が必要なことは、多変量解析を行う「因子」の決定です。
以下の図のように、「因子A」を最も調べたい因子だとして、残りの「因子B、C、D」は先行研究などから「ある結果」と因果関係があるとわかっている因子を投入することで、実際の「因子A」と「ある結果」の因果関係が調べられます。これで交絡因子を補正できていることになります。

用語の整理:従属変数と独立変数、目的変数と説明変数
論文を読んだり、研究を行うとどうしても専門用語がでてきます。
多変量解析の論文を読む、多変量解析を実践するときもその用語がでてきます。
先ほどの「ある結果」と「因子」には専門的な名前がつけられているので覚える必要があります。
ある結果→従属変数または目的変数
因子→独立変数または説明変数
(呼び方が2つずつあり、使用する統計ソフトや教科書、書いてある論文によっても異なるので注意が必要です・・・どちらか1つに統一してほしいですよね・・・)
「従属変数と独立変数」、「目的変数と説明変数」がセットになっているので、どちらを使用しても問題ありません。
これまでの図に当てはめるとこんな感じです。
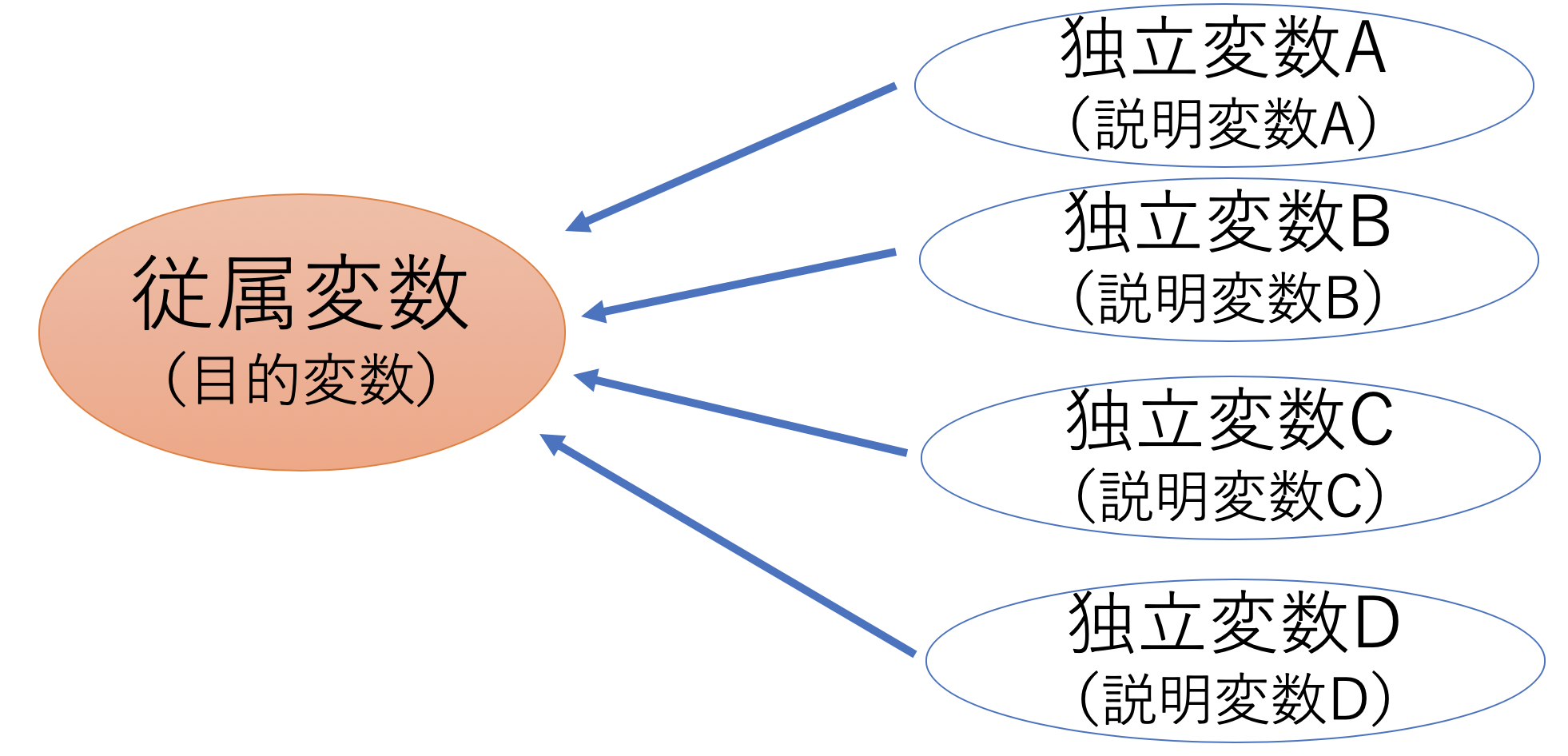
私は初めての論文で「従属変数と独立変数」を使用して、それ以来こちらを使うので、このサイトではこちらで統一させていただきます。
スポンサードサーチ
多変量解析の統計手法
多変量解析の使い分け
多変量解析には、調べたい内容、従属変数の種類によって使い分ける必要があります。
以下に具体的な方法をまとめています。
| 従属変数 | 回帰モデル |
| 連続変数、順序変数の場合 | ➡︎ 重回帰分析 |
| 名義変数(2値変数)の場合 | ➡︎ ロジスティック回帰分析 |
| 生存期間の場合 | ➡︎ Cox比例ハザード回帰分析 |
独立変数(説明変数)の決定と投入可能個数
「ある変数:従属変数」と「因子:独立変数」の因果関係を調査するときに、「何をいれるか(独立変数を何にするか)」を決めるには、まず「何個いれてもいいか」をを知るところから始まります。
なんでもかんでも投入すると統計学的に問題がおきて信頼性がなくなります。
(論文を読んでいると、時折怪しい解析をしているのがあるので、この知識があると論文の読む力にもなります)
これは、使われた多変量解析の種類とデータの量で決まります。
以下に、投入できる独立変数の個数を回帰モデルごとに表示します。
| 回帰モデル | 独立変数の個数 |
| 重回帰分析 | 総症例数を15で割った数まで(10で割った数としている教科書もあり) |
| ロジスティック回帰分析 | イベントありとなし(2値の)小さい方の数を10で割った数まで |
| Cox比例ハザート回帰分析 | イベントありの数を10で割った数まで |
参考教科書:みんなの医療統計(多変量解析編) P208
*教科書によっても違いがあるので、若干の個数の変化は許容されるかもしれませんが、おおよそ上記の個数が目安となります。
*独立変数のデータ尺度は、連続変数でも順序変数でも、名義変数でもなんでも投入可能です。
ここで研究の大前提ですが、本来は研究したいテーマを決定すると、統計手法も研究計画段階で明確になります。
そのため、調査したい内容によって必要な症例数も把握できるはずです。(例えば重回帰分析で独立変数を5つ投入したければ最低でも50例以上は必要)
ですので、症例数がわかってから、独立変数の個数を決定するのではなく、研究計画書の段階で投入したい独立変数を決定して、それに応じて集めなければいけない症例数をイメージすることが重要だと思います。
(といっても前向き研究ではこれでいいですが、後ろ向き研究では症例数ありきの独立変数の個数になるのは仕方ないですけどね)
また、独立変数に何を選択するかは、自分が調査したい変数と先行研究で従属変数と関連性が明らかになっている変数を選択する必要があります。
例えば年齢が影響することがわかっていても(先行研究より)、独立変数に投入しないと交絡因子を確認できたことにならないので、質の低い研究になってしまいます。
こう考えると、多変量解析に関してはいかに症例数が重要なのかが身にしみますよね。
多変量解析を行なっている論文には「ステップワイズ法」を使用していることを多く見かけます。
様々な教科書にも、「変数の決定にはステップワイズ法を使いましょう」などとよく書かれています。
そんな「ステップワイズ法」を絶対使ってはいけないといっている先生方もいるので紹介します。
ステップワイズ法を用いると最終モデルに到達するまでに、多くのP値が計算され、データを細かく見すぎることで再現性が大きな問題になることが知られています。
(中略)「ステップワイズ法を用いたら、即クビだ!」と上司に言われていたんですよ。
引用文献:みんなの医療統計 多変量解析編 p218-221
私も公衆衛生の権威の先生に直接ステップワイズは使ってはいけないと指導され、「ステップワイズはなんでもいいから有意差を出すために製薬会社が医師にむけてつくった方法(その先生の意見)だから、統計的にはよくない」と指導されました。
しかし書籍にものっている方法ですので、専門家でも意見がわかれるのかもしれません。
(私はこのように指導されましたので、ステップワイズは使用したことがありません)
多変量解析の結果の解釈
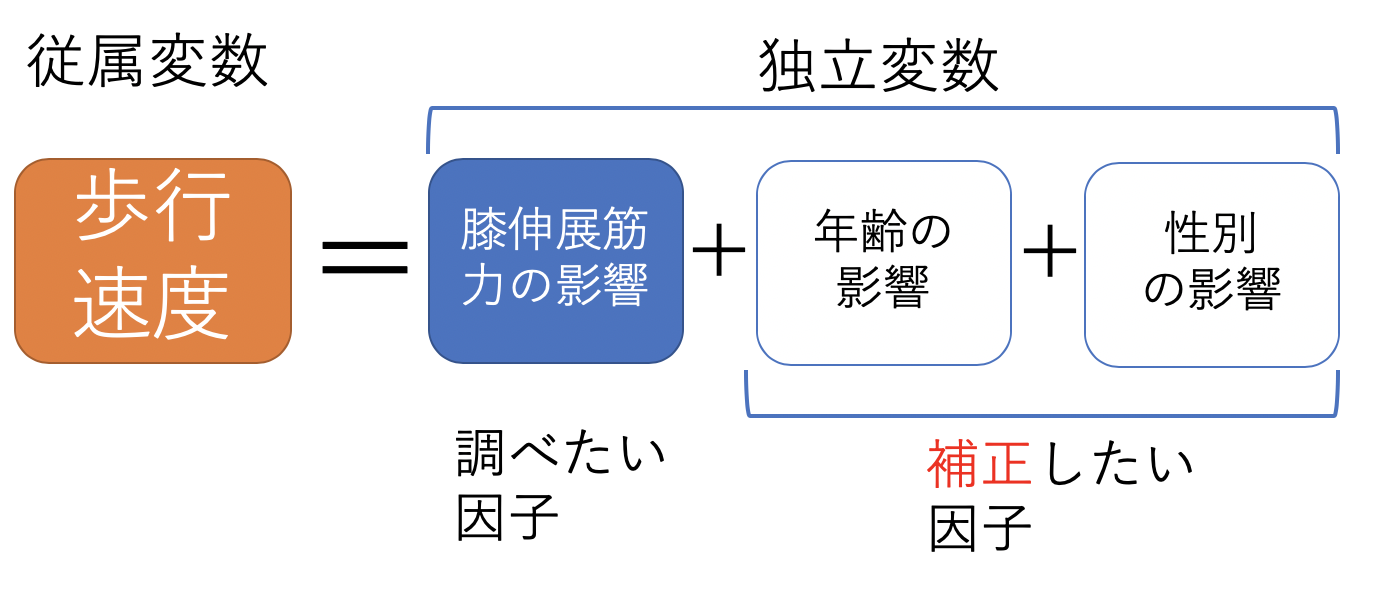
多変量解析を上記の統計手法で行うと「従属変数の予測式」を作成できます。
簡単にすると以下のようなイメージ図です。

この式を作成することで、どの変数が強く影響していて、どの変数が影響していないのかが分かることになります。ですので、交絡因子も考慮したことになります。
これを利用すれば、ある変数を「補正」した結果も示すこともできます。
例えば、「通常歩行速度(従属変数)」は、「年齢」と「性別」を補正して、「膝伸展筋力」が影響するかを調べることができます。(以下にイメージ図を示す)
スポンサードサーチ
まとめ
今回は多変量解析について簡単にまとめてみました。
「ある結果」と「因子」について因果関係を調査したいことは多いと思いますし、論文でも多変量解析は多く使用されています。
「交絡因子」を理解して、それを補正して因果関係を調査できるとても重要な方法です。
実践方法に関しては、EZRを使用して解説していきたいと思いますが、今回は概要を知っていただけたらと思いましてまとめてみました。
参考になれば幸いです。






“多変量解析とは?〜多変量解析の種類と使い分け〜” への2件のフィードバック